

Contents
Sometimes application developers write SQL. This is dangerous. A database seems like a friendly place to store the most important data you own. It can also be a trap that takes down your web application.
Very often we find that developers are well-schooled in languages like Python, C++, C#, and the like. (And if you are, don’t hesitate to apply for a role with us). SQL is different game entirely. Being a smart developer, does not automatically make anyone knowledgeable in SQL. It makes one smart enough to be dangerous. The results may be flaky application behavior, major performance degradation under load, or major pain two years from now when data size is much larger.
So here are simple tips to quickly make you a better SQL developer today. This article mostly focuses on what to do. A follow-up article will focus more on why. For now, follow these rules and your SQL will be better immediately. For reference, we are using modern versions of SQL Server.
In short, these are what we’ve seen as common mistakes and misconceptions from novice SQL developers.
Think About Data Types & Data Lengths.
Understand datatype sizes. For example, tinyint is 1 byte. or 0–255 range. If you are storing an age, a tinyint will suffice. If you are storing an email address, then 254 characters will suffice. No need to reserve 5000 characters. Do not store a datetime when a simple date will do.
Efficiency here reduces data size on disk, in-memory, in archives, and over the network (if the database is being replicated, which it is).
NULL is not zero. NULL is nothing.
Do not compare NULL with = or !=. Use IS NOT NULL, or IS NULL. NULL is not a value so it cannot be compared to anything. It can only be or not be. Read more.
SCOPE_IDENTITY Wins.
To return the identity of an added row, use SCOPE_IDENTITY 99% of the time. Not @@IDENTITY nor IDENT_CURRENT.
Sorting Is Expensive & It Does Not Scale.
If results must be sorted, do not use ORDER BY in SQL. Instead, sort in the calling web service or in the web application.
Cost of sorting is basically NLogN (see purple).
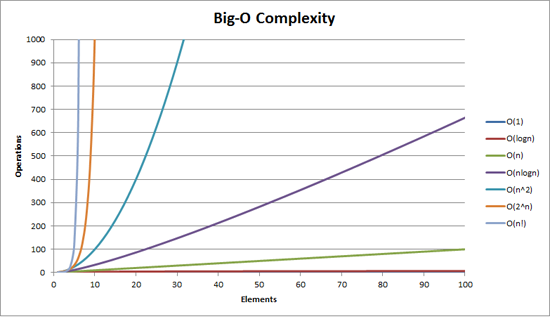
Sorting becomes much more expensive as the data size increases.
A typical architecture is that many application servers, which can scale horizontally, are hitting a single database server. Where possible, prefer to incur the cost of sorting on the cheap, distributed application servers. Give the expensive database server a break!
In fact, you may consider trying to never use keywords other than SELECT, FROM, WHERE, LIMIT. All of the other manipulation of data and business logic should be done in those scalable application servers.
SELECT *: I am insanely lazy.
SELECT * is an unacceptable piece of code. It will return every column on a table. Even columns added after your query was created. This results in potential waste of RAM on the database server, and on the calling application server.
NOLOCK is Not Your Default. Neither is READ UNCOMMITTED.
Unless you know what NOLOCK is being used for, do not use it and definitely do not copy/paste it. It may yield unpredictable results. NOLOCK is not a magical keyword that makes the query way faster. Transactions Block. Keep them brief.
Shorter transactions result in higher concurrency. Longer transactions result in longer locking and blocking, and a slower overall database activity.
Do Not Call Functions In a WHERE Clause.
This a performance problem. Do not make function calls in the WHERE clause that include the columns being filtered in the WHERE clause. The function will need to be called for each record in the result set. This is obviously slow.
SELECT Date
FROM [dbo].[MyTable]
WHERE dateadd(d,5,Date) > getdate()
Know What an Execution Plan Is.
Like any piece of code in any language, what you think SQL does to a system can be quite different from what it actually does to a system. Execution plans reveal the truth. Much like a performance profiler would. Execution plans are enlightening. Become educated.
Test Against Production Data.
Almost everything is fast when executed against small data sets. Test with real-world-sized data sets. Better yet, generate huge data sets bigger than production. Then run performance tests.
Share this article: